Overthewire: Natas Level 0 to 5
Table of Contents
Overthewire - Natas
This series on the overthewire webpage challenges you to think outside the box and more about communication between client and server in order to find the hidden flag on the website for the next level. The structure of the challenge is that for each level you require a user name and password to authenticate to the next level challenge website. The username is natas[X] with X being the current level (e.g. natas5 for level 5), the corresponding URL is “http: //natas[X].natas.labs.overthewire.org/", X again being the level number e.g. “http://natas5.natas.labs.overthewire.org/" for the fifth level, and the password consists of 32 alphanumeric characters.
And now without further ado, let’s get to it:
natas0
So we begin with the first level - natas0 - and have a look at the instructions. The page tells us the credentials for the first level:
Username: natas0
Password: natas0
URL: http://natas0.natas.labs.overthewire.org
So we go to the URL and have a look, enter the credentials
and…:

On the natas0 webpage, we have a look at the structure of the website using Mozilla Firefox website inspector (“Press F12 to open ist.").
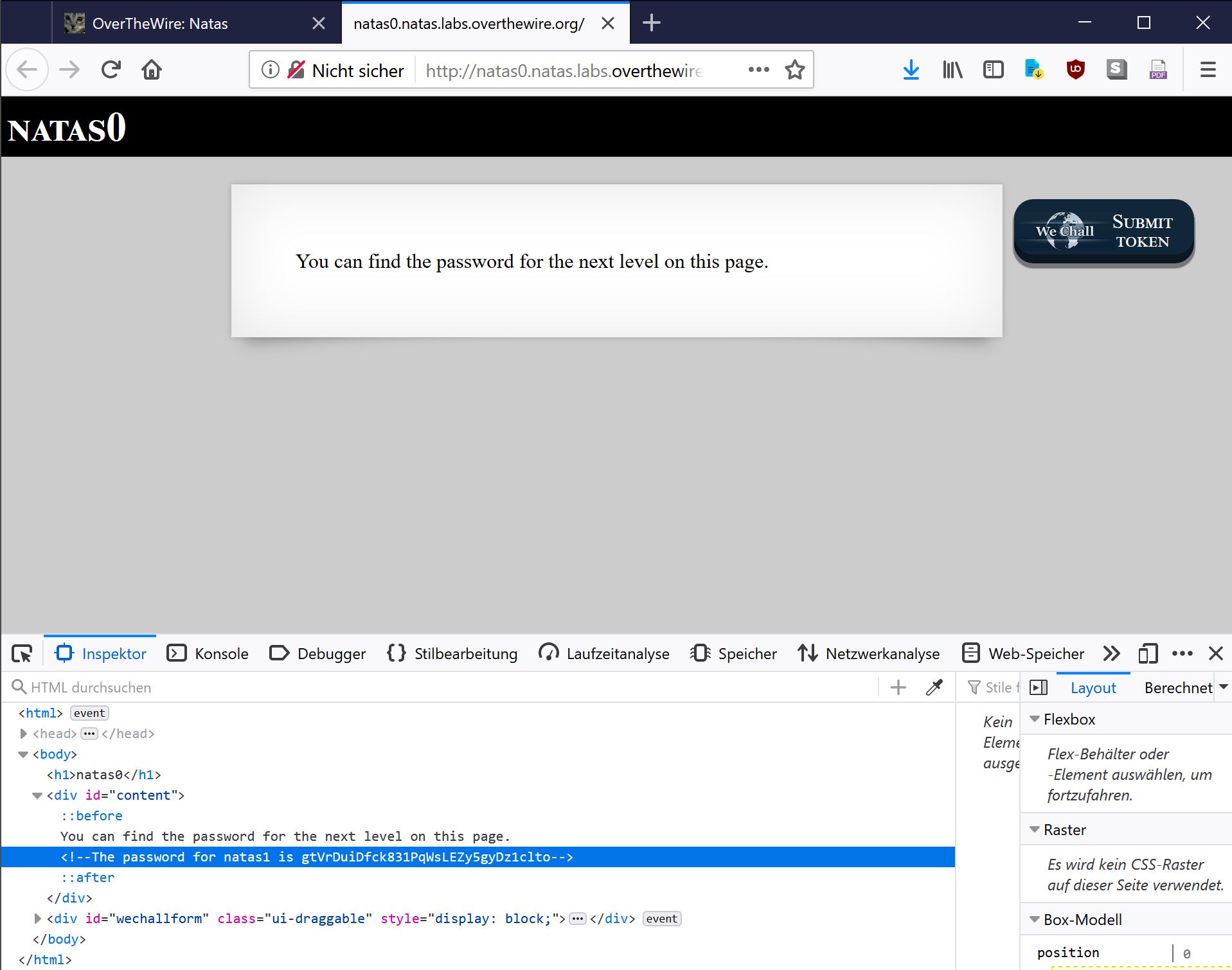
Et voilà, the password for natas1 is written as an HTML comment:
Spoiler natas1:
Username: natas1Password: gtVrDuiDfck831PqWsLEZy5gyDz1clto
URL: http://natas1.natas.labs.overthewire.org
natas1
Inside on the natas1 webpage, we again use the website inspector and browse through the structure of the website:

Spoiler natas2:
Username: natas2Password: ZluruAthQk7Q2MqmDeTiUij2ZvWy2mBi
URL: http://natas2.natas.labs.overthewire.org
```
natas2
Inside natas2 website, we again use the website inspector and browse through the structure of the website. However, this time there is no HTML comment with passwrd on the webpage. However we find an img tag with the source “files/pixel.png”. That is odd.

Ok what if we entered that URL, thus included the “files/pixel.png” directory inside our URL path?
We get:
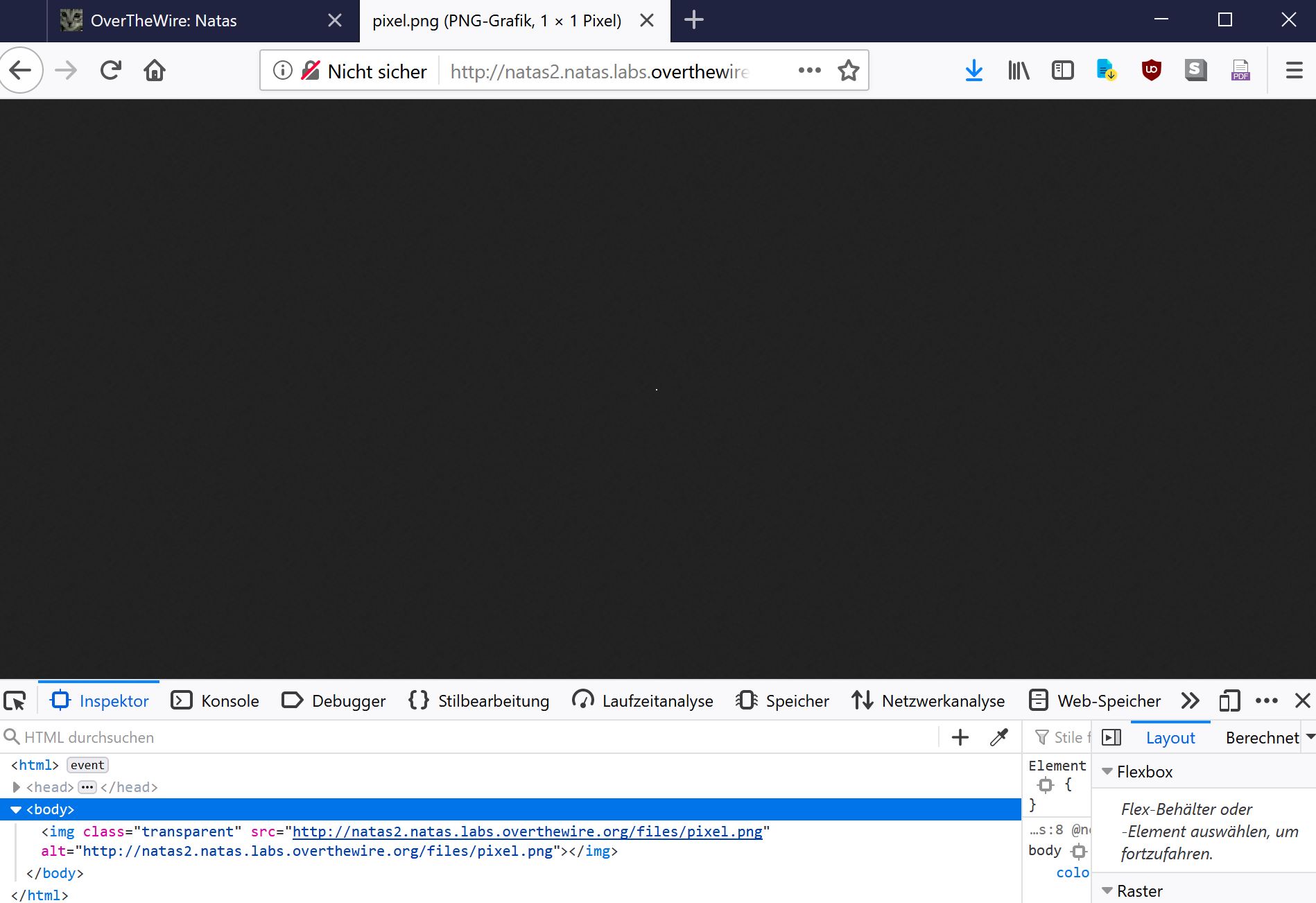
Ok maybe we do not need to see the pixel, but the content of the “files” directory?
So let’s try that:

Now we have a look at the content of the “users.txt” file:

Spoiler natas3:
Username: natas3
Password: sJIJNW6ucpu6HPZ1ZAchaDtwd7oGrD14
URL: http://natas3.natas.labs.overthewire.org
natas3
Wow those websites are so informative: “There is nothing on this page”. I bet there is, so let’s browse through the website’s structure again using the Mozilla Firefox website inspector:
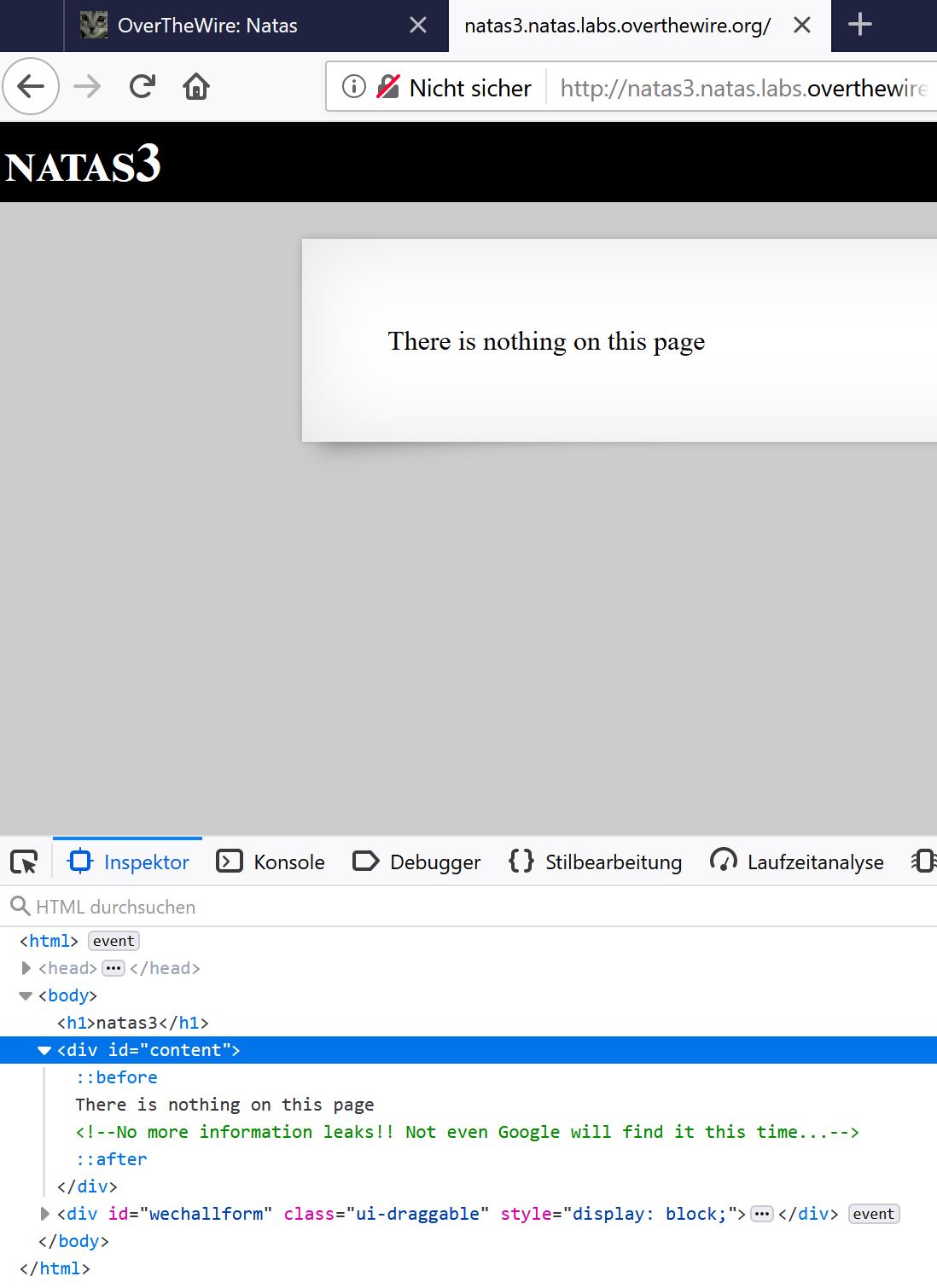
Alright, “No more information leaks!! Not even Google will find it this time… “, what do we make of it?
If we use Google to find out information about how Google crawls website’s we eventually end up at the "Robots exclusion standard".
It is used by websites to communicate with web crawlers and other web robots, informing them in detail about which parts of the website should be crawled or left alone. All of this is specified in the “robots.txt” file. Alright, let’s have a look, whether we have a robots.txt at this website:
And indeed, if we include “robots.txt” in the URL path and go to “http://natas3.natas.labs.overthewire.org/robots.txt", we see:

So there must again be a folder on the server called “s3cr3t”.
Let’s go there:

If we now open the “users.txt” file, we finally get the password:

Spoiler natas4:
Username: natas4Password: Z9tkRkWmpt9Qr7XrR5jWRkgOU901swEZ
URL: http://natas4.natas.labs.overthewire.org
natas4
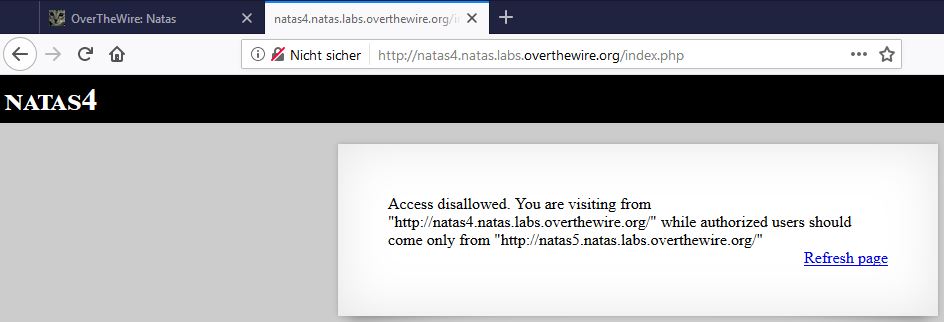
On the natas4 website, we realize this is the first time so far, that the actual content of the page is helpful! “Access disallowed. You are visiting from "" while authorized users should come only from "http://natas5.natas.labs.overthewire.org/"".
So we came from “nowhere”, while authorized users should visit the website coming from the natas5 URL, the exact page that we want to get access to. That is weird.
Well the page also tells us to reload the site. So let’s do that:
Alright let’s dig deeper. We open again the website inspector and look at the network traffic.

So what is this referer field? Let’s Google and check it: HTTP referer
“The HTTP referer is an optional HTTP header field that identifies the address of the webpage which is linked to the resource being requested. By checking the referrer, the new webpage can see where the request originated.”
Alright “checking the referrer, the new webpage can see where the request originated”! That is just what we need. So what if we could change the referer to “http://natas5.natas.labs.overthewire.org/"?
Let’s try this and use a proxy to help us accomplish that task by intercepting our HTTP request, changing the referer and then forwarding the HTTP request. For that task we have several possibilities on how to proceed:
We can use a professional network analyzing tool like "burp" or we can write a network proxy with intercepting and changing network traffic capabilities in python.
For now, we use burp. First we download and install it or simply execute the shell file on our machine, depending on your own OS flavor. After startup we choose “Temporary Project” and then “Start Burp”.
Alright, after startup burp can be super overwhelming.
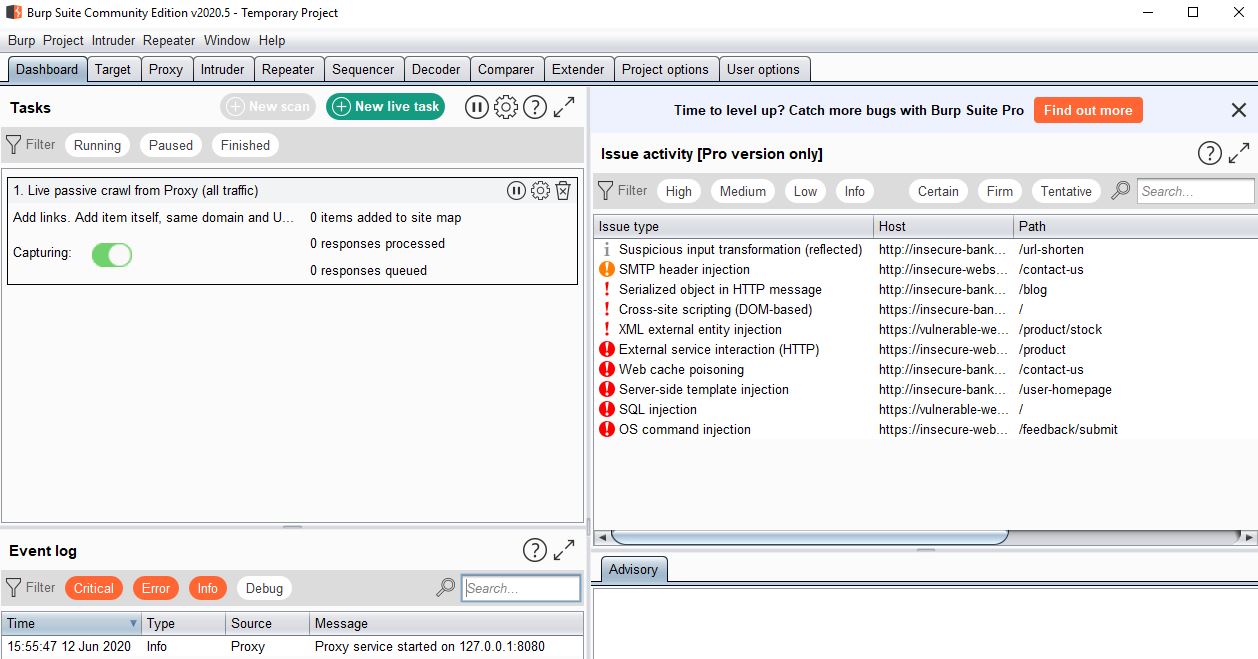
The most important information for us here is, a proxy has been started on localhost on port 8080 (127.0.0.1:8080).
So we set our browser to redirect traffic through that proxy. Therefore we open Firefox Settings, go to “General” and then to “Network Settings”. Since we only want to redirect http traffic, we enter “127.0.0.1” and “8080” into the proxy configuration.
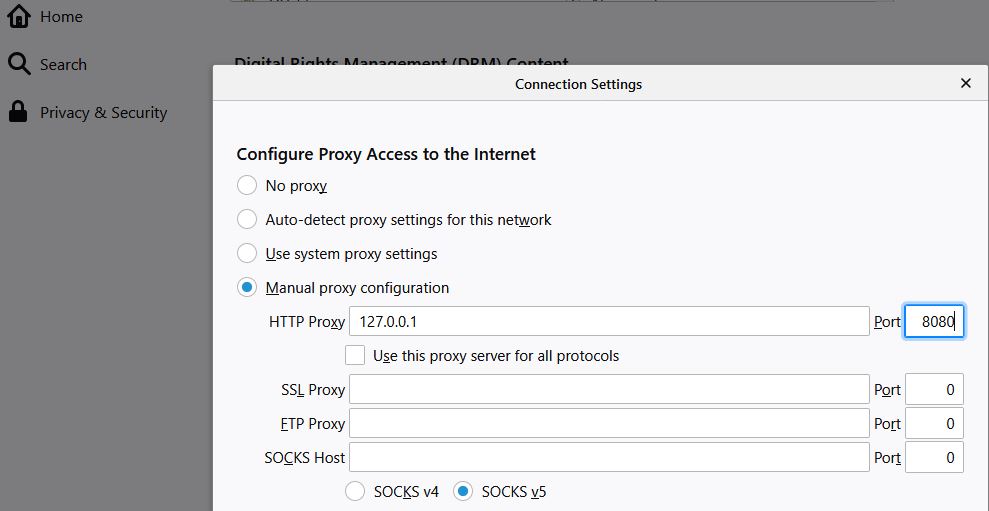
Ok now our setup is done. What happens when we reload our natas4 webpage now with burp turned on, the proxy set up and Firefox redirecting all HTTP traffic through that proxy? Let’s find out:

It works. We intercept our HTTP request via burp, however we don’t see the referer field. Here we could try manually writing the referer field into request or simply reload the page:
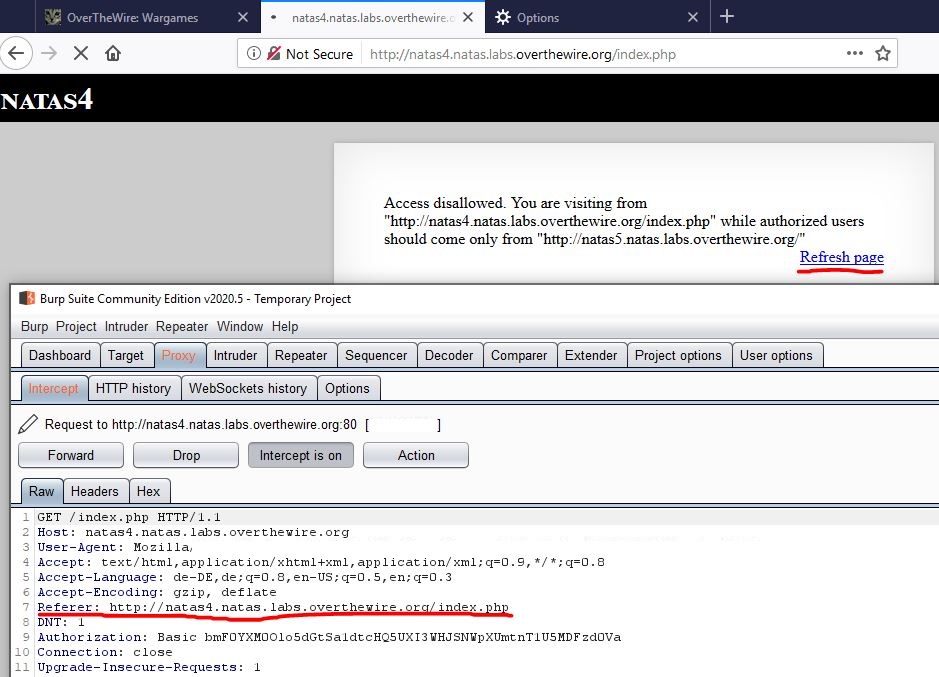
Perfect! So now we change this payload to “Referer: http://natas5.natas.labs.overthewire.org”. Let’s do this:
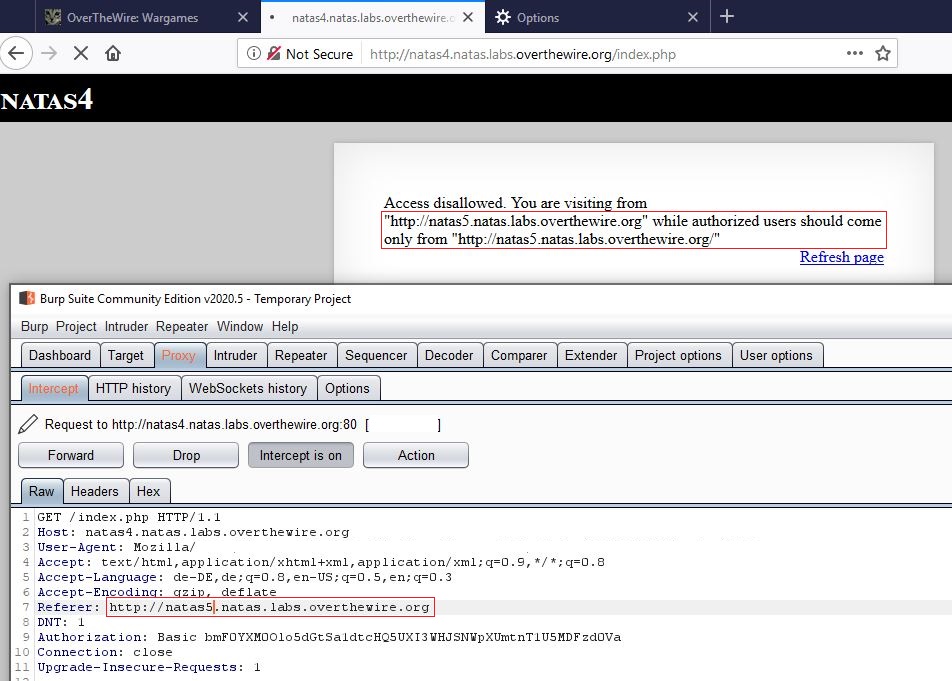
We changed the referer field to “Referer: http://natas5.natas.labs.overthewire.org”. Why don’t we get access? I forgot a simple slash “/". It even says so on the website… So let’s do it again now with including the slash:

We gained access!
Spoiler natas5:
Username: natas5Password: iX6IOfmpN7AYOQGPwtn3fXpbaJVJcHfq
URL: http://natas5.natas.labs.overthewire.org
natas5
The website tell us “Access disallowed. You are not logged in”. Alright. How do we gain access?
Let’s intercept our traffic and analyse what we have:

Hm that didn’t lead us anywhere. However last time we also needed to refresh the page so the natas website can inform our browser about any new changes. So let’s do that:
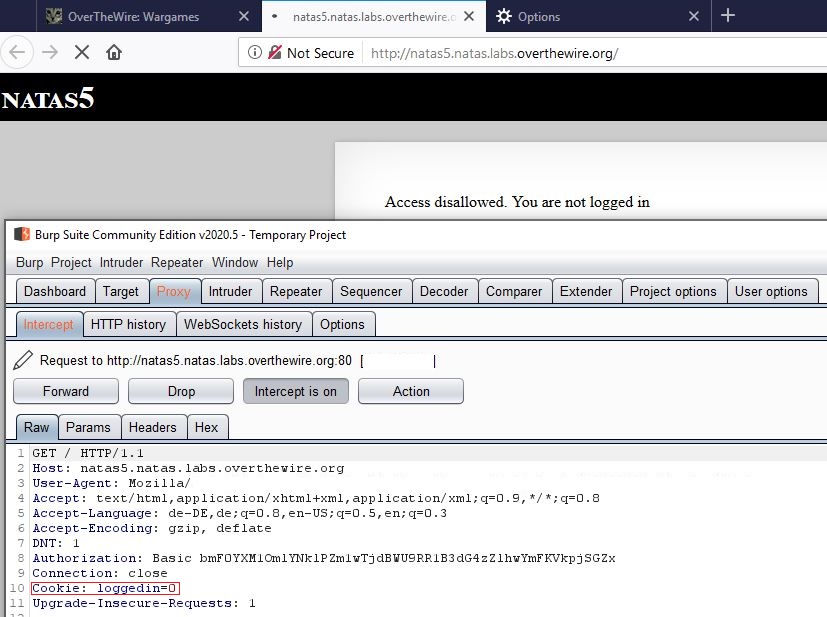
Ok. Out of the blue, there is now a Cookie: “loggedin=0” Can it be that simple? Simply set that to 1 and we are in???

Spoiler natas6:
Username: natas6
Password: aGoY4q2Dc6MgDq4oL4YtoKtyAg9PeHa1
URL: http://natas6.natas.labs.overthewire.org
Wrap Up
Alright folks, so far we have covered natas level 0 to 5. We introduced the Firefox Network Inspection tool, URL paths, the robots exclusion standard, local network proxies such as burp (yes for future solutions we will use a custom python based network proxy), intercepting and changing the payload of HTTP requests and briefly touched on session management.
See you soon!